Mô hình thu được cho độ chính xác dự đoán lên đến 99,5%, cho thấy tính khả thi cao trong ứng dụng thực tiễn. Dựa trên mô hình này, nhóm nghiên cứu đã phát triển phần mềm DGA Diagnostic Tool nhằm hỗ trợ kỹ sư vận hành trong việc phát hiện sớm và phân loại sự cố tiềm ẩn của MBA. Ứng dụng này không chỉ nâng cao hiệu quả chẩn đoán mà còn góp phần vào chiến lược bảo trì dự báo, giảm thời gian gián đoạn và nâng cao độ tin cậy hệ thống.
Nghiên cứu khẳng định tính hiệu quả của việc tích hợp công nghệ trí tuệ nhân tạo vào các phương pháp giám sát thiết bị điện truyền thống, mở ra hướng tiếp cận thông minh trong quản lý tài sản ngành năng lượng.
1. GIỚI THIỆU (INTRODUCTION)
MBA được xem là trái tim của hệ thống điện, đóng vai trò quan trọng trong việc chuyển đổi và phân phối điện năng. Các sự cố liên quan đến MBA đều ảnh hưởng lớn đến hoạt động sản xuất kinh doanh và đời sống người dân tại khu vực[2], [3].
Cách điện bên trong MBA bao gồm giấy cách điện và dầu cách điện[4], [5]. Cách điện chịu tác động của ứng suất nhiệt và điện trường liên tục có thể dẫn đến quá trình lão hoá tăng nhanh và hư hỏng tiềm ẩn bên trong[2]. Các lỗi trong máy biến áp tạo ra năng lượng để phá vỡ các liên kết hóa học trong dầu cách điện. Năng lượng thấp phá vỡ các liên kết C-H (338 kJ/mol). Năng lượng cao và/hoặc nhiệt độ cao phá vỡ các liên kết C-C đồng thời tái hợp chúng thành khí với liên kết đơn C-C (607 kJ/mol), liên kết đôi C=C (720 kJ/mol) hoặc liên kết ba C≡C (960 kJ/mol) . Các loại khí được tạo ra bao gồm H2, CH4, C2H6, C2H4, C2H2, CO2 và CO[6]. Dựa trên nồng độ và tỷ số các khí sinh ra, phương pháp phân tích khí hoà tan (DGA) giúp xác định lỗi nặng/nhẹ bên trong MBA, từ đó có hướng điều chỉnh chế độ vận hành hoặc xử lý khi cần thiết[7]. Để chẩn đoán sự cố MBA, các tổ chức tiêu chuẩn quốc tế và nhà nghiên cứu đã xây dựng một số phương pháp như: phương pháp khí chính, phương pháp tỷ lệ Dornenburg[4], [6], phương pháp tỷ lệ Rogers[6], phương pháp tỷ lệ IEC[8], [9], phương pháp Duval[6], [10]. Các phương pháp trên dựa vào mối tương quan giữa nồng độ và tỷ lệ khí hòa tan để xác định hư hỏng bên trong MBA. Nhưng lại có nhược điểm như lỗi ranh giới mã hóa quá lớn, tiêu chí giá trị tới hạn và một số trường hợp không xác định được nguyên nhân làm ảnh hưởng lớn đến độ tin cậy của kết quả phân tích chẩn đoán[11].
Bảng 1. Các lỗi sự cố chính bên trong MBA
|
Tên lỗi
|
Mã lỗi
|
|
Phóng điện cục bộ
|
PD
|
|
Phóng điện năng lượng thấp
|
D1
|
|
Phóng điện năng lượng cao
|
D2
|
|
Quá nhiệt mức thấp <300°C
|
T1
|
|
Quá nhiệt mức trung bình 300÷700°C
|
T2
|
|
Quá nhiệt mức cao >700°C
|
T3
|
|
Bình thường
|
N
|
Ngoài các mã lỗi chính như bảng 1[8], [12], mã lỗi hỗn hợp DT[8], [13] (Phóng điện kèm quá nhiệt); và các lỗi bổ sung: S (Khí tản), R (Phản ứng xúc tác), O (Quá nhiệt giấy hoặc dầu cách điện), C (Cacbon hoá giấy cách điện)[6].
Vài năm gần đây, mô hình máy học (machine learning) phát triển một cách bùng nổ, được ứng dụng trong rất nhiều lĩnh vực khác nhau. Với thế mạnh có khả năng học hỏi, xử lý dữ liệu lớn, việc ứng dụng mô hình máy học để xây dựng công cụ hỗ trợ chẩn đoán sự cố tiềm ẩn bên trong MBA dựa trên kết quả DGA là cần thiết.
Nghiên cứu này đề xuất sử dụng thuật toán FastTreeOva để xây dựng một mô hình chẩn đoán hiệu quả hơn. FastTreeOva được lựa chọn nhờ khả năng xử lý dữ liệu đa biến, tạo mô hình dễ hiểu và độ chính xác cao. Mục tiêu của nghiên cứu là đánh giá khả năng của FastTreeOva trong việc phân loại các loại lỗi DGA phổ biến và xác định các biến DGA quan trọng. Kết quả nghiên cứu này sẽ đóng góp vào việc nâng cao độ tin cậy của hệ thống điện bằng cách phát hiện sớm các sự cố tiềm ẩn trong máy biến áp.
2. CƠ SỞ LÝ THUYẾT/PHƯƠNG PHÁP NGHIÊN CỨU (THEORETICAL FRAMEWORD/METHODS)
Trong lĩnh vực khai phá dữ liệu, cây quyết định (Decision Tree – DT) là một mô hình dự đoán thuộc lớp các bài toán phân lớp dùng để xác định lớp của các đối tượng cần dự đoán. Bản chất cây quyết định dựa vào dãy các luật IF … THEN để dự đoán lớp của đối tượng.
Mỗi nút trong (internal node) của DT tương ứng với một biến, đường nối giữa một nút trong với nút con của nó thể hiện một giá trị cụ thể biến đó. Mỗi nút lá (leaf) đại diện cho giá trị dự đoán. Cây quyết định học để dự đoán giá trị của các biến phân loại bằng cách dựa vào tập dữ liệu huấn luyện (training data) để chọn ra nút gốc (root node) để phân tách cây bằng cách tính độ tăng thông tin (Information Gain - IG), quá trình phân tách được thực hiện theo một quy trình lặp đi lặp lại cho đến khi không thể tiếp tục thực hiện việc phân tách cây được nữa[14], [15].
Cây quyết định được chia thành hai loại:
- Cây hồi quy dùng để dự đoán giá trị của biến phân loại có kiểu dữ liệu giá trị như dự đoán doanh thu, lợi nhuận và giá thành sản phẩm. Thuật toán phổ biến dùng để xây dựng cây phân loại và hồi quy là Classification and Regression Trees (CART).
- Cây phân lớp dùng để dự đoán giá trị của biến phân loại có kiểu dữ liệu phi giá trị như dự đoán khả năng mua hàng, khả năng bị bệnh, kết quả học tập của sinh viên (xuất sắc, giỏi, khá, trung bình, yếu). Thuật toán phổ biến dùng để xây dựng cây phân lớp là ID3, J48, C4.5, C5.0[15].
FastTreeOva (FastTree One-vs-All) là một biến thể của mô hình FastTree, được thiết kế đặc biệt cho các bài toán phân loại nhiều lớp. FastTreeOva mở rộng khả năng này để xử lý các tác vụ phân loại đa lớp thông qua cách tiếp cận One-vs-All (OvA)[14]. Trong phương pháp One-vs-All, một mô hình phân loại đa lớp được chia thành nhiều bài toán phân loại nhị phân. Với mỗi lớp, một mô hình riêng được huấn luyện để phân biệt lớp đó với tất cả các lớp còn lại. Điều này tạo ra tổng cộng n mô hình phân loại nhị phân, với n là số lượng lớp. Khi dự đoán, mỗi mô hình sẽ đưa ra dự đoán của mình, và lớp có điểm số cao nhất từ một trong các mô hình sẽ được chọn là lớp dự đoán cuối cùng. FastTreeOva sử dụng cây quyết định tăng cường gradient (Gradient Boosted Decision Trees - GBDT) làm cơ sở cho mỗi mô hình nhị phân. Cây GBDT là một phương pháp học máy mạnh mẽ, có khả năng xử lý dữ liệu không tuyến tính và tương tác giữa các đặc trưng mà không cần phải chuyển đổi thủ công. Cách tiếp cận này giúp FastTreeOva không chỉ mạnh mẽ và linh hoạt mà còn khá hiệu quả về mặt tính toán. FastTreeOva thích hợp cho các bài toán có số lượng lớp lớn, với dữ liệu đầu vào có thể là dạng văn bản, số, hoặc các loại dữ liệu phức tạp khác. Điểm mạnh của FastTreeOva bao gồm khả năng tự động xử lý các đặc trưng, hiệu suất cao trong việc dự đoán, và khả năng mô hình hóa các mối quan hệ phức tạp giữa các đặc trưng. FastTreeOva là một công cụ mạnh mẽ trong việc giải quyết các bài toán phân loại đa lớp, đặc biệt là trong các tình huống đòi hỏi một mô hình có khả năng tự động hóa cao và hiệu suất dự đoán tốt[16].
3. KẾT QUẢ NGHIÊN CỨU/TÍNH TOÁN/MÔ PHỎNG VÀ THẢO LUẬN (RESULTS AND DISCUSSION)
Sơ đồ khối các bước thực hiện nghiên cứu:
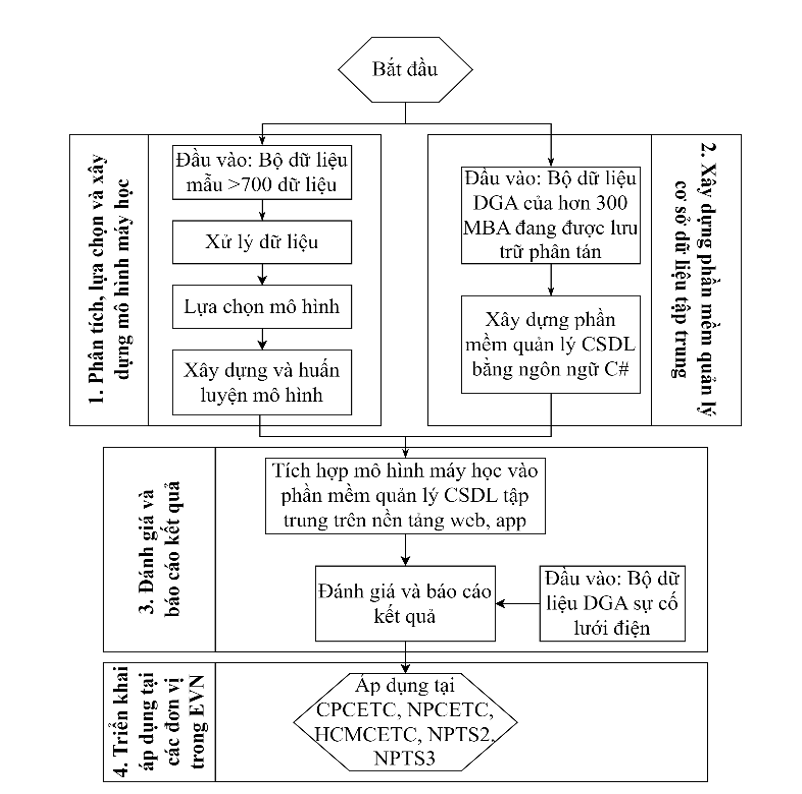
 Hình 1. Sơ đồ khối thực hiện nghiên cứu
Hình 1. Sơ đồ khối thực hiện nghiên cứu
3.1. Phân tích, lựa chọn và xây dựng mô hình máy học
Quá trình phân tích, lựa chọn và xây dựng mô hình máy học gồm các bước như sau:
3.1.1 Bước 1: Thu thập dữ liệu mẫu phục vụ huấn luyện
Nhóm tác giả đã phân tích, đánh giá nguồn cơ sở dữ liệu của hơn 300 MBA trên lưới điện miền Trung và Tây Nguyên do Công ty TNHH MTV Thí nghiệm điện miền Trung (CPCETC) lưu giữ từ năm 2002 đến nay. Từ đó lựa chọn được 231 dữ liệu (116 dữ liệu liệu sự cố và 115 dữ liệu bình thường). Ngoài ra thu thập thêm 240 dữ liệu của Công ty TNHH Thí nghiệm điện miền Nam (SPCETC), 201 dữ liệu từ Institute of Electrical and Electronics Engineers (IEEE) [1], và 50 dữ liệu từ một số bài báo quốc tế[2] [18], [19]. Chi tiết xem bảng 2
Bộ dữ liệu huấn luyện (DGA_Training) với 722 dữ liệu có độ tin cậy cao, số lượng lỗi dạng quá nhiệt chiếm khoảng 43%, lỗi dạng phóng điện chiếm 41% và bình thường 16%. Đây là cơ sở cốt lõi để lựa chọn mô hình phù hợp và chính xác.
Bảng 2. Dữ liệu huấn luyện
|
Nguồn dữ liệu
|
PD
|
D1
|
D2
|
T1
|
T2
|
T3
|
N
|
Tổng
|
|
CPCETC
|
13
|
2
|
24
|
1
|
29
|
47
|
115
|
231
|
|
SPCETC
|
23
|
32
|
63
|
76
|
18
|
28
|
0
|
240
|
|
IEEE
|
15
|
49
|
56
|
19
|
25
|
37
|
0
|
201
|
|
[18]
|
0
|
0
|
6
|
4
|
2
|
7
|
1
|
20
|
|
[19]
|
1
|
7
|
2
|
3
|
3
|
14
|
0
|
30
|
|
|
52
|
90
|
151
|
103
|
77
|
133
|
116
|
722
|
|
Phần trăm
|
7%
|
13%
|
21%
|
14%
|
11%
|
18%
|
16%
|
|
3.1.2. Bước 2: Xử lý dữ liệu
Dữ liệu thô ban đầu được tiền xử lý: chuẩn hoá, xử lý các giá trị ngoại lệ, phân tích dữ liệu,… để đạt định dạng phù hợp cho việc huấn luyện mô hình, chia thành 7 phân lớp được gán nhãn theo mã lỗi (PD, D1, D2, T1, T2, T3, N)[16].
3.1.3. Bước 3: Lựa chọn mô hình
Công cụ AutoML – một tính năng của nền tảng ML.NET được phát triển bởi Microsoft. Công cụ này có ưu điểm cho phép duyệt nhanh các mô hình có sẳn và độ chính xác có thể đạt được mà không cần viết lập trình[14]. AutoML tự động lựa chọn mô hình tối ưu phù hợp với bộ dữ liệu. Kết quả thu được 3 mô hình có độ chính xác tốt nhất như sau:
Bảng 3. Ba mô hình có độ chính xác tốt nhất được AutoML đề xuất
|
STT
|
Mô hình
|
Độ chính xác
|
|
1
|
FastTreeOva
|
99,5%
|
|
2
|
LightGbmMulti
|
98,4%
|
|
3
|
FastForestOva
|
95,5%
|
Với độ chính xác được AutoML đề xuất như bảng 3, nhóm tác giả quyết định lựa chọn mô hình máy học FastTreeOva có độ chính xác cao nhất để xây dựng mô hình chẩn đoán.
3.1.4. Bước 4: Xây dựng và huấn luyện mô hình
Bộ dữ liệu DGA_Training được sử dụng để huấn luyện mô hình, được chia thành 2 nhóm: nhóm huấn luyện chiếm 80% số mẫu và nhóm kiểm tra chiếm 20% số mẫu[16]. Độ chính xác thu được khi sử dụng mô hình FastTreeOva là 99,5% trên các bộ dữ liệu cho nghiên cứu này.
Để đảm bảo độ chính xác đáng tin cậy (ví dụ không có sự phù hợp quá mức, dữ liệu thử nghiệm không giống dữ liệu huấn luyện). Bộ dữ liệu (DGA_Evaluation) 539 dữ liệu được sử dụng để kiểm tra mô hình, gồm có 38 dữ liệu sự cố và 501 dữ liệu bình thường. Bộ dữ liệu DGA_Evaluation riêng biệt, chỉ dùng để kiểm tra sau khi hoàn thành quá trình máy học, không nằm trong bộ dữ liệu DGA_Training. Kết quả chẩn đoán của mô hình FastTreeOva đưa ra có độ chính xác như bảng 4.
Bảng 4. Kết quả kiểm tra đối với mô hình FastTreeOva trên bộ dữ liệu DGA_Evaluation
|
STT
|
Lỗi
|
Số mẫu kiểm tra
|
Số mẫu kiểm tra chính xác
|
Độ chính xác
|
|
1
|
T1
|
3
|
3
|
100%
|
|
2
|
T2
|
1
|
1
|
100%
|
|
3
|
T3
|
9
|
9
|
100%
|
|
4
|
PD
|
7
|
7
|
100%
|
|
5
|
D1
|
2
|
2
|
100%
|
|
6
|
D2
|
16
|
15
|
93,8%
|
|
7
|
N
|
501
|
500
|
99,8%
|
|
Tổng cộng
|
539
|
537
|
99,6%
|
Độ chính xác () được xác định bằng tỷ số giữa số mẫu kiểm tra chính xác (s) và số mẫu kiểm tra (Ω).
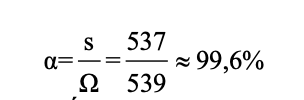

 Như vậy, kết quả huấn luyện cho thấy mô hình máy học FastTreeOva có độ chính xác 99,6% trên bộ dữ liệu DGA_Evaluation.
Như vậy, kết quả huấn luyện cho thấy mô hình máy học FastTreeOva có độ chính xác 99,6% trên bộ dữ liệu DGA_Evaluation.
Kết quả đánh giá trên các tập dữ liệu DGA_Training và DGA_Evaluation cho thấy mô hình FastTreeOva đạt được độ chính xác cao. Điều này khẳng định tiềm năng ứng dụng của mô hình trong việc phân tích chẩn đoán tại CPCETC.
3.2. Xây dựng phần mềm quản lý cơ sở dữ liệu tập trung
Xây dựng phần mềm quản lý cơ sở dữ liệu DGA của CPCETC từ năm 2002 đến nay và kết hợp ứng dụng mô hình FastTreeOva thành công cụ chẩn đoán cùng với các phương pháp chẩn đoán truyền thống CPCETC đang áp dụng.
3.3. Đánh giá và báo cáo kết quả
Tích hợp mô hình máy học FastTreeOva đã huấn luyện vào phần mềm quản lý cơ sở dữ liệu, xây dựng giao diện trên nền tảng web, iOS, Android.
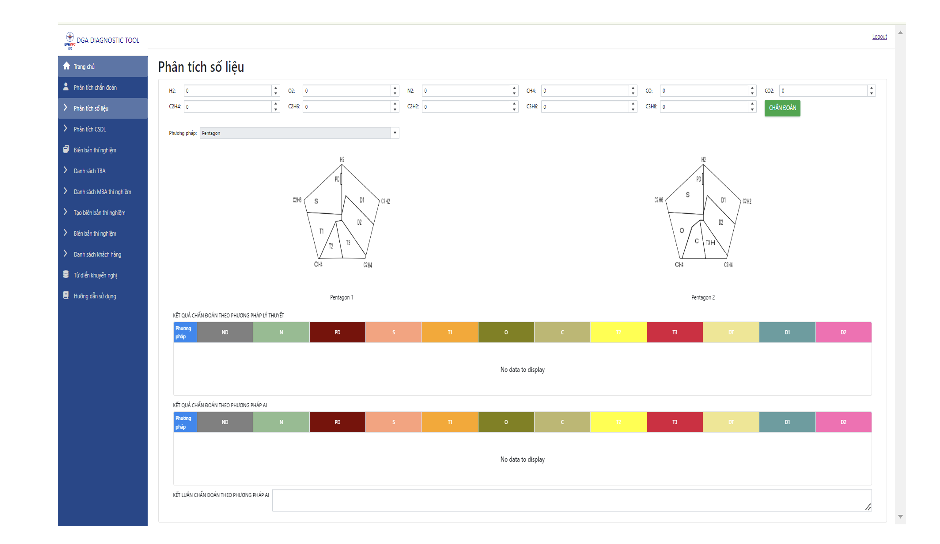
 Hình 2. Giao diện phần mềm trên web
Hình 2. Giao diện phần mềm trên web
Trong thời gian áp dụng phần mềm, trên lưới điện miền Trung và Tây nguyên có 09 MBA xảy ra hiện tượng bất thường về DGA. Bảng 5 cho thấy, kết quả chẩn đoán của mô hình FastTreeOva đưa ra tương đồng với kết quả chẩn đoán của kỹ sư CPCETC. Mô hình FastTreeOva đã khắc phục được hạn chế của các phương pháp truyền thống. Đối với MBA T1A ĐMT miền Trung có 03 phương pháp truyền thống (IEC, Roger, NPT[20]) không đưa ra chẩn đoán. Tuy nhiên mô hình máy học vẫn đưa ra chẩn đoán và kết quả tương đương kết luận của kỹ sư CPCETC. Ngoài ra, việc ứng dụng mô hình máy học giúp rút ngắn thời gian của người kỹ sư trong công tác chẩn đoán. Dữ liệu đầu vào được nhập và trích xuất tự động từ thiết bị thí nghiệm, giảm thiểu tối đa các thao tác của con người, nâng cao hiệu quả công việc và năng suất lao động.
Bảng 5. Kết quả chẩn đoán của mô hình so với các phương pháp truyền thống và CPCETC
|
TT
|
Tên
MBA
|
Thành phần khí (ppm)
|
Kết quả chẩn đoán
theo từng phương pháp
|
Kết luận CPCETC
|
Mô hình MH
|
|
H2
|
CH4
|
C2H6
|
C2H4
|
C2H2
|
IEC
|
Roger
|
NPT
|
Duval Triangle
|
Duval Pentagon
|
-
|
T1 Hội An
|
34,9
|
102,3
|
53,2
|
215,9
|
0,0
|
T3
|
T3
|
T3
|
T3
|
T3
|
T3
|
T3
|
|
2
|
T1 Thăng Bình
|
556,0
|
11,6
|
3,6
|
2,1
|
0,0
|
ND
|
ND
|
PD
|
T1
|
PD
|
PD
|
PD
|
|
3
|
T2 NMTĐ KaNak
|
185,7
|
222,4
|
106,5
|
862,1
|
18,3
|
T3
|
T3
|
T3
|
T3
|
T3
|
T3
|
T3
|
|
4
|
T1A ĐMT miền Trung
|
365,5
|
27,3
|
14,3
|
25,1
|
35,3
|
ND
|
ND
|
ND
|
D2
|
D1
|
D2
|
D2
|
|
5
|
064733-41 Đăk Rlấp
|
597,3
|
116,7
|
32,7
|
134,2
|
247,7
|
D2
|
D2
|
D2
|
D2
|
D2
|
D2
|
D2
|
|
6
|
VN1334 Tam Thăng
|
47,7
|
6,5
|
1,7
|
12,3
|
13,5
|
D2
|
D2
|
D2
|
D2
|
D2
|
D2
|
D2
|
|
7
|
TD41 Đăk Hà
|
10055
|
960,4
|
829,8
|
7,92
|
0,0
|
PD
|
D1
|
PD
|
PD
|
S
|
PD
|
PD
|
|
8
|
T03 NMĐG Đăk Hoà
|
34,5
|
10,2
|
4,6
|
67,5
|
129,3
|
D2
|
D2
|
D2
|
D2
|
D2
|
D2
|
D2
|
|
9
|
T1 NMTĐ Trà Linh 3
|
27,1
|
484,4
|
678,6
|
2809,4
|
0,0
|
T3
|
T3
|
T3
|
T3
|
T3
|
T3
|
T3
|
Từ kết quả chẩn đoán của kỹ sư CPCETC, đơn vị quản lý vận hành phối hợp nhà chế tạo tách MBA ra khỏi vận hành để kiểm tra, sửa chữa. Trong quá trình rút ruột MBA kiểm tra, đã xác định chính xác hư hỏng, một số hình ảnh như trong bảng 6 dưới đây:
Bảng 6. Một số hình ảnh sự cố bên trong MBA

3.4. Triển khai áp dụng tại các đơn vị trong EVN
Nghiên cứu này được triển khai áp dụng tại CPCETC và một số đơn vị thí nghiệm điện trong EVN như NPCETC, HCMCETC, NPTS2, NPTS3. Thông qua kiểm chứng thực tế, mô hình máy học chứng minh được sự tiện lợi, chính xác trong các kết quả chẩn đoán, được các đơn vị đánh giá cao và đề xuất mở rộng phạm vi ứng dụng để góp phần nâng cao hiệu quả quản lý và vận hành lưới điện.
Điều này còn chứng tỏ thêm mô hình được huấn luyện dựa trên bộ dữ liệu của CPCETC là một mô hình tiên tiến, một phương pháp chẩn đoán mới phù hợp với đặc điểm vận hành lưới điện tại Việt Nam, có thể được áp dụng rộng rãi trong EVN để hỗ trợ cho việc phân tích chẩn đoán tình trạng vận hành MBA.
4. KẾT LUẬN VÀ KIẾN NGHỊ (CONCLUSIONS)
Nghiên cứu này đề xuất mô hình FastTreeOva xây dựng công cụ hỗ trợ kỹ sư chẩn đoán sự cố tiềm ẩn bên trong MBA dựa trên kết quả phân tích sắc ký khí hoà tan. Độ chính xác cao dựa trên hai bộ dữ liệu DGA_Training và DGA_Evaluation. Trong quá trình áp dụng thực tế tại CPCETC từ tháng 12/2023, mô hình FastTreeOva đưa ra kết quả chẩn đoán chính xác đối với 180 MBA 110kV hiện đang vận hành trên lưới điện miền Trung và Tây Nguyên.
Phạm vi dữ liệu nguồn dữ liệu được tiếp cận là những lỗi điển hình như T1, T2, T3, PD, D1, D2, N. Song sự cố trong MBA phát sinh từ rất nhiều nguyên nhân khác nhau và phức tạp: quá tải, sự cố ngắn mạch, quá nhiệt, lão hoá cách điện,… Một số trường hợp khí cháy phát sinh do vật liệu cách điện không tương thích, hoặc khí cháy cao nhưng tốc độ sinh khí không tăng. Những trường hợp này ảnh hưởng đến kết quả của mô hình máy học đưa ra do thiếu dữ liệu đầu vào. Định hướng thu thập thêm dữ liệu MBA phát triển trong tương lai.
Với những hiệu quả thực tế to lớn như vậy, ứng dụng trí tuệ nhân tạo hỗ trợ kỹ sư phân tích chẩn đoán lỗi MBA dựa trên kết quả DGA là một hướng đi đúng đắn và cần thiết. Nghiên cứu này không chỉ cung cấp một công cụ chẩn đoán hiệu quả mà còn mở ra hướng mới trong việc ứng dụng công nghệ máy học vào lĩnh vực bảo dưỡng và quản lý máy biến áp. Kết quả nghiên cứu góp phần nâng cao độ tin cậy và an toàn của hệ thống điện, đồng thời giảm thiểu rủi ro và chi phí liên quan đến việc bảo trì và sửa chữa máy biến áp.
5. TÀI LIỆU THAM KHẢO (REFERENCE)
[1] E. Li, L. Wang, and B. Song, “Fault diagnosis of power transformers with membership degree,” IEEE Access, vol. 7, pp. 28791–28798, 2019, doi: 10.1109/ACCESS.2019.2902299.
[2] I. B. M. Taha, S. Ibrahim, and D. E. A. Mansour, “Power transformer fault diagnosis based on DGA using a convolutional neural network with noise in measurements,” IEEE Access, vol. 9, pp. 111162–111170, 2021, doi: 10.1109/ACCESS.2021.3102415.
[3] H. Hu, X. Ma, and Y. Shang, “A novel method for transformer fault diagnosis based on refined deep residual shrinkage network,” IET Electr Power Appl, vol. 16, no. 2, pp. 206–223, Feb. 2022, doi: 10.1049/elp2.12147.
[4] Suwarno, H. Sutikno, R. A. Prasojo, and A. Abu-Siada, “Machine learning based multi-method interpretation to enhance dissolved gas analysis for power transformer fault diagnosis,” Heliyon, vol. 10, no. 4, Feb. 2024, doi: 10.1016/j.heliyon.2024.e25975.
[5] Y. Benmahamed, O. Kherif, M. Teguar, A. Boubakeur, and S. S. M. Ghoneim, “Accuracy improvement of transformer faults diagnostic based on DGA data using SVM-BA classifier,” Energies (Basel), vol. 14, no. 10, May 2021, doi: 10.3390/en14102970.
[6] IEEE Guide for the Interpretation of Gases Generated in Mineral Oil-Immersed Transformers, C57.104-2019. Transformers Committee of the IEEE Power and Energy Society, 2019.
[7] B. A. Thango, “On the Application of Artificial Neural Network for Classification of Incipient Faults in Dissolved Gas Analysis of Power Transformers,” Mach Learn Knowl Extr, vol. 4, no. 4, pp. 839–851, Dec. 2022, doi: 10.3390/make4040042.
[8] Mineral oil-filled electrical equipment in service – Guidance on the interpretation of dissolved and free gases analysis, IEC60599, 4th ed. Internationanl electrotechniccal commission, 2022.
[9] M. Duval and A. dePablo, “Interpretation of Gas-In-Oil Analysis Using New IEC Publication 60599 and IEC TC 10 Databases,” IEEE Electrical Insulation Magazine, vol. 17, no. 2, pp. 31–41, 2001.
[10] M. Duval and L. Lamarre, “The duval pentagon-a new complementary tool for the interpretation of dissolved gas analysis in transformers,” IEEE Electrical Insulation Magazine, vol. 30, no. 6, pp. 9–12, Nov. 2014, doi: 10.1109/MEI.2014.6943428.
[11] N. Van Le, “Application of artificial intelligence in diagnosis of power transformer incipient faults,” 2013 26th IEEE Canadian Conference on Electrical and Computer Engineering (CCECE). IEEE, Da Nang, 2013. doi: 10.1109/CCECE.2013.6567700.
[12] S. Agrawal and A. K. Chandel, “Transformer incipient fault diagnosis based on probabilistic neural network,” in 2012 Students Conference on Engineering and Systems, SCES 2012, 2012. doi: 10.1109/SCES.2012.6199110.
[13] O. E. Gouda, S. H. El-Hoshy, and H. H. E. L. Tamaly, “Condition assessment of power transformers based on dissolved gas analysis,” IET Generation, Transmission and Distribution, vol. 13, no. 12, pp. 2299–2310, Jun. 2019, doi: 10.1049/iet-gtd.2018.6168.
[14] R. Chalupnik, K. Bialas, I. Jozwiak, and M. Kedziora, Acquiring and Processing Data Using Simplified EEG-based Brain-Computer Interface for the Purpose of Detecting Emotions. 2021.
[15] N. Van Hieu and D. T. T. Ha, “A system for dianosing autism based on the decision tree,” The University of Danang - Journal of Science and Technology, vol. 1, no. 11, pp. 101–104, 2015.
[16] M. M. et al. Magaji, “Fast Tree Model for Predicting Network Security Incidents.,” in 2022 5th Information Technology for Education and Development (ITED). IEEE, 2022, pp. 1–6.
[17] A. Nanfak, S. Eke, C. H. Kom, R. Mouangue, and I. Fofana, “Interpreting dissolved gases in transformer oil: A new method based on the analysis of labelled fault data,” IET Generation, Transmission and Distribution, vol. 15, no. 21, pp. 3032–3047, Nov. 2021, doi: 10.1049/gtd2.12239.
[18] G. Odongo, R. Musabe, and D. Hanyurwimfura, “A multinomial dga classifier for incipient fault detection in oil-impregnated power transformers,” Algorithms, vol. 14, no. 4, Apr. 2021, doi: 10.3390/a14040128.
[19] Y. Liu, B. Song, L. Wang, J. Gao, and R. Xu, “Power transformer fault diagnosis based on dissolved gas analysis by correlation coefficient-DBSCAN,” Applied Sciences (Switzerland), vol. 10, no. 13, Jul. 2020, doi: 10.3390/app10134440.
[20] Regulations for operation and repair. National Power Transmission Corporation, 2018.
Nguyễn Văn Ngà, Đào Trực, Trần Đình Thọ, Ngô Huy Chiến, Nguyễn Văn Lục, Trần Huy Vũ
Share